Статистический факторный анализ. Факторный анализ в статистических пакетах Statistica Statgraphics и. Факторный анализ рентабельности
ФАКТОРНЫЙ АНАЛИЗ
Идея факторного анализа
При исследовании сложных объектов, явлений, систем факторы, определяющие свойства этих объектов, очень часто невозможно измерить непосредственно, а иногда неизвестно даже их число и смысл. Но для измерения могут быть доступны другие величины, так или иначе зависящие от интересующих нас факторов. Причем, когда влияние неизвестного интересующего нас фактора проявляется в нескольких измеряемых признаках или свойствах объекта, эти признаки могут обнаруживать тесную связь между собой и общее число факторов может быть гораздо меньше, чем число измеряемых переменных.
Для выявления факторов, определяющих измеряемые признаки объектов, используются методы факторного анализа
В качестве примера применения факторного анализа можно указать изучение свойств личности на основе психологических тестов. Свойства личности не поддаются прямому измерению. О них можно судить только по поведению человека или характеру ответов на вопросы. Для объяснения результатов опытов их подвергают факторному анализу, который и позволяет выявить те личностные свойства, которые оказывают влияние на поведение индивидуума.
В основе различных методов факторного анализа лежит следующая гипотеза: наблюдаемые или измеряемые параметры являются лишь косвенными характеристиками изучаемого объекта, в действительности существуют внутренние (скрытые, латентные, не наблюдаемые непосредственно) параметры и свойства, число которых мало и которые определяют значения наблюдаемых параметров. Эти внутренние параметры принято называть факторами.
Цель факторного анализа – сконцентрировать исходную информацию, выражая большое число рассматриваемых признаков через меньшее число более ёмких внутренних характеристик явления, которые, однако, не поддаются непосредственному измерению
Установлено, что выделение и последующее наблюдение за уровнем общих факторов даёт возможность обнаруживать предотказные состояния объекта на очень ранних стадиях развития дефекта. Факторный анализ позволяет отслеживать стабильность корреляционных связей между отдельными параметрами. Именно корреляционные связи между параметрами, а также между параметрами и общими факторами содержат основную диагностическую информацию о процессах. Применение инструментария пакета Statistica при выполнении факторного анализа исключает необходимость использования дополнительных вычислительных средств и делает анализ наглядным и понятным для пользователя.
Результаты факторного анализа будут успешными, если удается дать интерпретацию выявленных факторов, исходя из смысла показателей, характеризующих эти факторы. Данная стадия работы весьма ответственная; она требует чёткого представления о содержательном смысле показателей, которые привлечены для анализа и на основе которых выделены факторы. Поэтому при предварительном тщательном отборе показателей для факторного анализа следует руководствоваться их смыслом, а не стремлением к включению в анализ как можно большего их числа.
Сущность факторного анализа
Приведём несколько основных положений факторного анализа. Пусть для матрицы Х измеренных параметров объекта существует ковариационная (корреляционная) матрица C , где р – число параметров, n – число наблюдений. Путем линейного преобразования X =QY +U можно уменьшить размерность исходного факторного пространства Х до уровня Y , при этом р "<<р . Это соответствует преобразованию точки, характеризующей состояние объекта в j -мерном пространстве, в новое пространство измерений с меньшей размерностью р ". Очевидно, что геометрическая близость двух или множества точек в новом факторном пространстве означает стабильность состояния объекта.
Матрица Y содержит ненаблюдаемые факторы, которые по существу являются гиперпараметрами, характеризующими наиболее общие свойства анализируемого объекта. Общие факторы чаще всего выбирают статистически независимыми, что облегчает их физическую интерпретацию. Вектор наблюдаемых признаков Х имеет смысл следствия изменения этих гиперпараметров.
Матрица U
состоит из остаточных факторов, которые включают в основном ошибки измерения признаков x
(i
). Прямоугольная матрица Q
содержит факторные нагрузки, определяющие линейную связь между признаками и гиперпараметрами.
Факторные нагрузки – это значения коэффициентов корреляции каждого из исходных признаков с каждым из выявленных факторов. Чем теснее связь данного признака с рассматриваемым фактором, тем выше значение факторной нагрузки. Положительный знак факторной нагрузки указывает на прямую (а отрицательный знак – на обратную) связь данного признака с фактором.
Таким образом, данные о факторных нагрузках позволяют сформулировать выводы о наборе исходных признаков, отражающих тот или иной фактор, и об относительном весе отдельного признака в структуре каждого фактора.
Модель факторного анализа похожа на модели многомерного регрессионного и дисперсионного анализа. Принципиальное отличие модели факторного анализа в том, что вектор Y – это ненаблюдаемые факторы, а в регрессионном анализе – это регистрируемые параметры. В правой части уравнения (8.1) неизвестными являются матрица факторных нагрузок Q и матрица значений общих факторов Y.
Для нахождения матрицы факторных нагрузок используют уравнениеQQ т =S–V,
где Q т – транспонированная матрица Q, V – матрица ковариаций остаточных факторов U, т.е. . Уравнение решается путем итераций при задании некоторого нулевого приближения ковариационной матрицы V(0).
После нахождения матрицы факторных нагрузок Q вычисляются общие факторы (гиперпараметры) по уравнению
Y=(Q т V -1)Q -1 Q т V -1 X
Пакет статистического анализа Statistica позволяет в диалоговом режиме вычислить матрицу факторных нагрузок, а также значения нескольких заранее заданных главных факторов, чаще всего двух – по первым двум главным компонентам исходной матрицы параметров.
Факторный анализ в системе Statistica
Рассмотрим последовательность выполнения факторного анализа на примере обработки результатов анкетного опроса работников предприятия . Требуется выявить основные факторы, которые определяют качество трудовой жизни.
На первом этапе необходимо отобрать переменные для проведения факторного анализа. Используя корреляционный анализ, исследователь пытается выявить взаимосвязь исследуемых признаков, что, в свою очередь, даёт ему возможность выделить полный и безызбыточный набор признаков путём объединения сильно коррелирующих признаков.
Если проводить факторный анализ по всем переменным, то результаты могут получиться не совсем объективными, так как некоторые переменные определяется другими данными, и не могут регулироваться сотрудниками рассматриваемой организации.
Для того чтобы понять, какие показатели следует исключить, построим по имеющимся данным матрицу коэффициентов корреляции в Statistica: Statistics/ Basic Statistics/ Correlation Matrices/ Ok. В стартовом окне этой процедуры Product-Moment and Partial Correlations (рис. 4.3) для расчёта квадратной матрицы используется кнопка One variable list. Выбираем все переменные (select all), Ok, Summary. Получаем корреляционную матрицу.
Если коэффициент корреляции изменяется в пределах от 0,7 до 1, то это означает сильную корреляцию показателей. В этом случае можно исключить одну переменную с сильной корреляцией. И наоборот, если коэффициент корреляции мал, можно исключить переменную из-за того, что она ничего не добавит к общей сумме. В нашем случае сильной корреляции между какими-либо переменными не наблюдается, и факторный анализ будем проводить для полного набора переменных.
Для запуска факторного анализа необходимо вызвать модуль Statistics/ Multivariate Exploratory Techniques (многомерные исследовательские методы)/ Factor Analysis (факторный анализ). На экране появится окно модуля Factor Analysis.

Для анализа выбираем все переменные электронной таблицы; Variables (переменные): select all, Ok. В строке Input file (тип файла входных данных) указывается Raw Data (исходные данные). В модуле возможны два типа исходных данных – Raw Data (исходные данные) и Correlation Matrix – корреляционная матрица.
В разделе MD deletion задаётся способ обработки пропущенных значений:
* Casewise – способ исключения пропущенных значений (по умолчанию);
* Pairwise – парный способ исключения пропущенных значений;
* Mean substitution – подстановка среднего вместо пропущенных значений.
Способ Casewise состоит в том, что в электронной таблице, содержащей данные, игнорируются все строки, в которых имеется хотя бы одно пропущенное значение. Это относится ко всем переменным. В способе Pairwise игнорируются пропущенные значения не для всех переменных, а лишь для выбранной пары.
Выберем способ обработки пропущенных значений Casewise.
Statistica обработает пропущенные значения тем способом, который указан, вычислит корреляционную матрицу и предложит на выбор несколько методов факторного анализа.
После нажатия кнопки Ok появляется окно Define Method of Factor Extraction (определить метод выделения факторов).
Верхняя часть окна является информационной. Здесь сообщается, что пропущенные значения обработаны методом Casewise. Обработано 17 наблюдений и 17 наблюдений принято для дальнейших вычислений. Корреляционная матрица вычислена для 7 переменных. Нижняя часть окна содержит 3 вкладки: Quick, Advanced, Descriptives.
Во вкладке Descriptives (описательные статистики) имеются две кнопки:
1- просмотреть корреляции, средние и стандартные отклонения;
2- построить множественную регрессию.
Нажав на первую кнопку, можно посмотреть средние и стандартные отклонения, корреляции, ковариации, построить различные графики и гистограммы.
Во вкладке Advanced, в левой части, выберем метод (Extraction method) факторного анализа: Principal components (метод главных компонент). В правой части выбираем максимальное число факторов (2). Задаётся либо максимальное число факторов (Max no of factors), либо минимальное собственное значение: 1 (eigenvalue).
Нажимаем Ok, и Statistica быстро произвёдет вычисления. На экране появляется окно Factor Analysis Results (результаты факторного анализа). Как говорилось ранее, результаты факторного анализа выражаются набором факторных нагрузок. Поэтому далее будем работать с вкладкой Loadings.

Верхняя часть окна – информационная:
Number of variables (число анализируемых переменных): 7;
Method (метод выделения факторов): Principal components (главных компонент);
Log (10) determinant of correlation matrix (десятичный логарифм детерминанта корреляционной матрицы): –1,6248;
Number of factors extracted (число выделенных факторов): 2;
Eigenvalues (собственные значения): 3,39786 и 1,19130.
В нижней части окна находятся функциональные кнопки, позволяющие всесторонне просмотреть результаты анализа, числено и графически.
Factor rotation – вращение факторов, в данном выпадающем окне можно выбрать различные повороты осей. С помощью поворота системы координат можно получить множество решений, из которого необходимо выбрать интерпретируемое решение.
Существуют различные методы вращения координат пространства. Пакет Statistica предлагает восемь таких методов, представленных в модуле факторного анализа. Так, например, метод варимакс соответствует преобразованию координат: вращение, максимизирующее дисперсию. В методе варимакс получают упрощённое описание столбцов факторной матрицы, сводя все значения к 1 или 0. При этом рассматривается дисперсия квадратов нагрузок фактора. Факторная матрица, получаемая с помощью метода вращения варимакс, в большей степени инвариантна по отношению к выбору различных множеств переменных.
Вращение методом квартимакс ставит целью аналогичное упрощение только по отношению к строкам факторной матрицы. Эквимакс занимает промежуточное положение? при вращении факторов по этому методу одновременно делается попытка упростить и столбцы, и строки. Рассмотренные методы вращения относятся к ортогональным вращениям, т.е. в результате получаются некоррелированные факторы. Методы прямого облимина и промакс вращения относятся к косоугольным вращениям, в результате которых получаются коррелированные между собой факторы. Термин?normalized? в названиях методов указывает на то, что факторные нагрузки нормируются, то есть делятся на квадратный корень из соответствующей дисперсии.
Из всех предлагаемых методов, мы сначала посмотрим результат анализа без вращения системы координат – Unrotated. Если полученный результат окажется интерпретируемым и будет нас устраивать, то на этом можно остановиться. Если нет, можно вращать оси и посмотреть другие решения.
Щёлкаем по кнопке "Factor Loading" и смотрим факторные нагрузки численно.

Напомним, что факторные нагрузки – это значения коэффициентов корреляции каждой из переменных с каждым из выявленных факторов.
Значение факторной нагрузки, большее 0,7 показывает, что данный признак или переменная тесно связан с рассматриваемым фактором. Чем теснее связь данного признака с рассматриваемым фактором, тем выше значение факторной нагрузки. Положительный знак факторной нагрузки указывает на прямую (а отрицательный знак? на обратную) связь данного признака с фактором.
Итак, из таблицы факторных нагрузок было выявлено два фактора. Первый определяет ОСБ – ощущение социального благополучия. Остальные переменные обусловлены вторым фактором.
В строке Expl. Var (рис. 8.5) приведена дисперсия, приходящаяся на тот или иной фактор. В строке Prp. Totl приведена доля дисперсии, приходящаяся на первый и второй фактор. Следовательно, на первый фактор приходится 48,5 % всей дисперсии, а на второй фактор – 17,0 % всей дисперсии, всё остальное приходится на другие неучтенные факторы. В итоге, два выявленных фактора объясняют 65,5 % всей дисперсии.

Здесь мы также видим две группы факторов – ОСБ и остальное множество переменных, из которых выделяется ЖСР – желание сменить работу. Видимо, имеет смысл исследовать это желание более основательно на основе сбора дополнительных данных.
Выбор и уточнение количества факторов
Как только получена информация о том, сколько дисперсии выделил каждый фактор, можно возвратиться к вопросу о том, сколько факторов следует оставить. По своей природе это решение произвольно. Но имеются некоторые общеупотребительные рекомендации, и на практике следование им даёт наилучшие результаты.
Количество общих факторов (гиперпараметров) определяется путём вычисления собственных чисел (рис. 8.7) матрицы Х в модуле факторного анализа. Для этого во вкладке Explained variance (рис. 8.4) необходимо нажать кнопку Scree plot. 
Максимальное число общих факторов может быть равно количеству собственных чисел матрицы параметров. Но с увеличением числа факторов существенно возрастают трудности их физической интерпретации.
Сначала можно отобрать только факторы, с собственными значениями, большими 1. По существу, это означает, что если фактор не выделяет дисперсию, эквивалентную, по крайней мере, дисперсии одной переменной, то он опускается. Этот критерий используется наиболее широко. В приведённом выше примере на основе этого критерия следует сохранить только 2 фактора (две главные компоненты).
Можно найти такое место на графике, где убывание собственных значений слева направо максимально замедляется. Предполагается, что справа от этой точки находится только "факториальная осыпь". В соответствии с этим критерием можно оставить в примере 2 или 3 фактора.
Из рис. видно, что третий фактор незначительно увеличивает долю общей дисперсии.
Факторный анализ параметров позволяет выявить на ранней стадии нарушение рабочего процесса (возникновение дефекта) в различных объектах, которое часто невозможно заметить путём непосредственного наблюдения за параметрами. Это объясняется тем, что нарушение корреляционных связей между параметрами возникает значительно раньше, чем изменение одного параметра. Такое искажение корреляционных связей позволяет своевременно обнаружить факторный анализ параметров. Для этого достаточно иметь массивы зарегистрированных параметров.
Можно дать общие рекомендации по использованию факторного анализа вне зависимости от предметной области.
* На каждый фактор должно приходиться не менее двух измеренных параметров.
* Число измерений параметров должно быть больше числа переменных.
* Количество факторов должно обосновываться, исходя из физической интерпретации процесса.
* Всегда следует добиваться того, чтобы количество факторов было намного меньше числа переменных.
Критерий Кайзера иногда сохраняет слишком много факторов, в то время как критерий каменистой осыпи иногда сохраняет слишком мало факторов. Однако оба критерия вполне хороши при нормальных условиях, когда имеется относительно небольшое число факторов и много переменных. На практике более важен вопрос о том, когда полученное решение может быть интерпретировано. Поэтому обычно исследуется несколько решений с большим или меньшим числом факторов, и затем выбирается одно наиболее осмысленное.
Пространство исходных признаков должно быть представлено в однородных шкалах измерения, т. к. это позволяет при вычислении использовать корреляционные матрицы. В противном случае возникает проблема "весов" различных параметров, что приводит к необходимости применения при вычислении ковариационных матриц. Отсюда может появиться дополнительная проблема повторяемости результатов факторного анализа при изменении количества признаков. Следует отметить, что указанная проблема просто решается в пакете Statistica путем перехода к стандартизированной форме представления параметров. При этом все параметры становятся равнозначными по степени их связи с процессами в объекте исследования.
Если в наборе исходных данных имеются избыточные переменные и не проведено их исключение корреляционным анализом, то нельзя вычислить обратную матрицу (8.3). Например, если переменная является суммой двух других переменных, отобранных для этого анализа, то корреляционная матрица для такого набора переменных не может быть обращена, и факторный анализ принципиально не может быть выполнен. На практике это происходит, когда пытаются применить факторный анализ к множеству сильно зависимых переменных, что иногда случается, например, в обработке вопросников. Тогда можно искусственно понизить все корреляции в матрице путём добавления малой константы к диагональным элементам матрицы, и затем стандартизировать её. Эта процедура обычно приводит к матрице, которая может быть обращена, и поэтому к ней применим факторный анализ. Более того, эта процедура не влияет на набор факторов, но оценки оказываются менее точными.
Факторное и регрессионное моделирование систем с переменными состояниямиСистемой с переменными состояниями (СПС) называется система, отклик которой зависит не только от входного воздействия, но и от обобщенного постоянного во времени параметра, определяющего состояние. Регулируемый усилитель или аттенюатор? это пример простейшей СПС, в котором коэффициент передачи может дискретно или плавно изменяться по какому-либо закону. Исследование СПС обычно проводится для линеаризованных моделей, в которых переходный процесс, связанный с изменением параметра состояния, считается завершённым.
Аттенюаторы, выполненные на основе Г-, Т- и П-образного соединения последовательно и параллельно включённых диодов получили наибольшее распространение. Сопротивление диодов под воздействием управляющего тока может меняться в широких пределах, что позволяет изменять АЧХ и затухание в тракте. Независимость фазового сдвига при регулировании затухания в таких аттенюаторах достигается с помощью реактивных цепей, включенных в базовую структуру. Очевидно, что при разном соотношении сопротивлений параллельных и последовательных диодов может быть получен один и тот же уровень вносимого ослабления. Но изменение фазового сдвига будет различным.
Исследуем возможность упрощения автоматизированного проектирования аттенюаторов, исключающего двойную оптимизацию корректирующих цепей и параметров управляемых элементов. В качестве исследуемой СПС будем использовать электрически управляемый аттенюатор, схема замещения которого приведена на рис. 8.8. Минимальный уровень затухания обеспечивается в случае малого сопротивления элемента Rs и большого сопротивления элемента Rp. По мере увеличения сопротивления элемента Rs и уменьшения сопротивления элемента Rp вносимое ослабление увеличивается.

Зависимости изменения фазового сдвига от частоты и затухания для схемы без коррекции и с коррекцией приведены на рис. 8.9 и 8.10 соответственно. В корректированном аттенюаторе в диапазоне ослаблений 1,3-7,7 дБ и полосе частот 0,01?4,0 ГГц достигнуто изменение фазового сдвига не более 0,2°. В аттенюаторе без коррекции изменение фазового сдвига в той же полосе частот и диапазоне ослаблений достигает 3°. Таким образом, фазовый сдвиг уменьшен за счет коррекции почти в 15 раз.


Будем считать параметры коррекции и управления независимыми переменными или факторами, влияющими на затухание и изменение фазового сдвига. Это даёт возможность с помощью системы Statistica провести факторный и регрессионный анализ СПС с целью установления физических закономерностей между параметрами цепи и отдельными характеристиками, а также упрощения поиска оптимальных параметров схемы.
Исходные данные формировались следующим образом. Для параметров коррекции и сопротивлений управления, отличающихся от оптимальных в большую и меньшую стороны на сетке частот 0,01?4 ГГц, были вычислены вносимое ослабление и изменение фазового сдвига.
Методы статистического моделирования, в частности, факторный и регрессионный анализ, которые раньше не использовались для проектирования дискретных устройств с переменными состояниями, позволяют выявить физические закономерности работы элементов системы. Это способствует созданию структуры устройства исходя из заданного критерия оптимальности. В частности, в данном разделе рассматривался фазоинвариантный аттенюатор как типичный пример системы с переменными состояниями. Выявление и интерпретация факторных нагрузок, влияющих на различные исследуемые характеристики, позволяет изменить традиционную методологию и существенно упростить поиск параметров коррекции и параметров регулирования.
Установлено, что использование статистического подхода к проектированию подобных устройств оправдано как для оценки физики их работы, так и для обоснования принципиальных схем. Статистическое моделирование позволяет существенно сократить объём экспериментальных исследований.
Результаты
- Наблюдение за общими факторами и соответствующими факторными нагрузками – это необходимое выявление внутренних закономерностей процессов.
- С целью определения критических значений контролируемых расстояний между факторными нагрузками следует накапливать и обобщать результаты факторного анализа для однотипных процессов.
- Применение факторного анализа не ограничено физическими особенностями процессов. Факторный анализ является как мощным методом мониторинга процессов, так и применим к проектированию систем самого различного назначения.
Jae-On Kim, Charles W. Mueller. Factor Analysis: Statistical Methods and Practical Issues (Eleventh Printing, 1986).
ПРЕДИСЛОВИЕ
Настоящая работа является продолжением книги Джэй-Он Кима и Чарльза У. Мьюллера «Введение в факторный анализ: что это такое и как им пользоваться», также опубликованной в серии «Quantitative Applications in the Social Sciences». Последняя является введением в метод факторного анализа; в ней даются ответы на вопросы читателя: «Для чего используется факторный анализ?» и «Какие предположения делаются при использовании этого метода?», но не затрагиваются вопросы применения факторного анализа к конкретным данным. В работе «Факторный анализ: статистические методы и практические вопросы» более подробно рассматриваются специфические примеры анализа данных, различные виды факторного анализа и ситуации, когда его применение наиболее полезно. Различие между конфирматорным и разведочным факторным анализом здесь обсуждается более детально, чем во «Введении в факторный анализ». Например, рассматриваются различные критерии для факторного вращения. Особенно полезным является обсуждение различных форм косоугольных вращений и интерпретации коэффициентов в факторном анализе. Дж.-О. Ким и Ч. У. Мьюллер также ставят вопрос о числе факторов, фигурирующих в разведочном факторном анализе, разбирают методы проверки гипотез в конфирматорном анализе и рассматривают проблему вычисления значений факторов. Предлагается словарь специальных терминов, а также ответы на вопросы, наиболее часто возникающие у пользователей факторного анализа, которые могут предостеречь их от многих ошибок. Математический аппарат достаточно скромный - приводятся только сведения из матричной алгебры.
Факторный анализ использовался в экономических задачах, в которых наличие сильно коррелированных параметров приводило к неверным результатам в регрессионном анализе. Ученые, занимающиеся общественно-политическими проблемами, сопоставляли всевозможные признаки наций с разными политическими и социально-экономическими характеристиками, пытаясь определить, какие из них наиболее важны при классификации наций (например, благосостояние и численность); социологи определяли «дружественные группы», изучая группы людей, симпатизирующих именно друг другу (а не другим индивидуумам). Психологи использовали метод факторного анализа для определения того, как люди воспринимают всевозможные «стимулы» и классификации людей в группы, соответствующие различным реакциям, а издатели применяли факторный анализ для изучения способов связывать отдельные элементы языка.
Как утверждают авторы, их работа не охватывает всех аспектов факторного анализа, так как он постоянно развивается. Тем не менее если читатель получит достаточно полное представление о том, как этот метод может быть использован, то можно считать, что авторы выполнили свою задачу.
Е. М. Асланер, редактор серии
Statistica 6 q. Подготовка корреляционной матрицы для факторного анализа q. Создание матрицы для факторного анализа q. Факторный анализ q. Выделение факторных нагрузок q. Построение факторной диаграммы
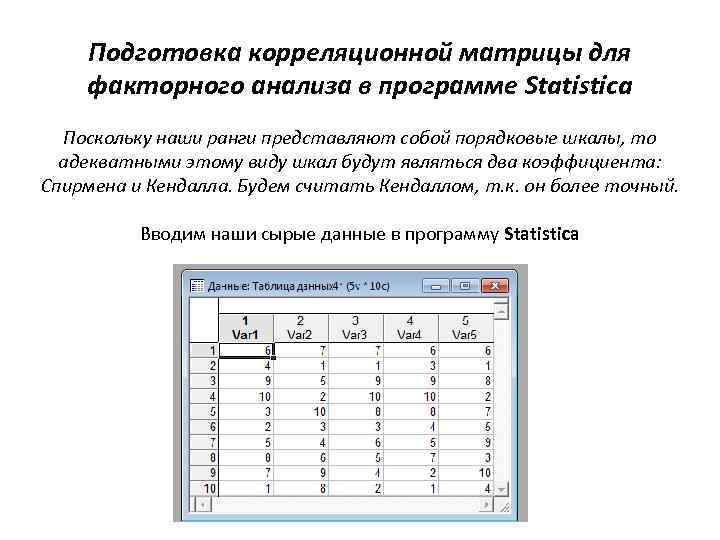 Подготовка корреляционной матрицы для факторного анализа в программе Statistica Поскольку наши ранги представляют собой порядковые шкалы, то адекватными этому виду шкал будут являться два коэффициента: Спирмена и Кендалла. Будем считать Кендаллом, т. к. он более точный. Вводим наши сырые данные в программу Statistica
Подготовка корреляционной матрицы для факторного анализа в программе Statistica Поскольку наши ранги представляют собой порядковые шкалы, то адекватными этому виду шкал будут являться два коэффициента: Спирмена и Кендалла. Будем считать Кендаллом, т. к. он более точный. Вводим наши сырые данные в программу Statistica




 Мы получили факторную матрицу, рассчитанную коэффициентом Кендалла, т. к. именно он является адекватным для наших данных, которые представляют собой шкалы порядка.
Мы получили факторную матрицу, рассчитанную коэффициентом Кендалла, т. к. именно он является адекватным для наших данных, которые представляют собой шкалы порядка.
 Создание матрицы для расчета ФА Теперь нужно создать матрицу такой структуры, по которой Statistica сможет осуществить факторный анализ. Необходимо, чтобы матрица, помимо значений корреляций между переменными, включала еще 4 строки под ними: 1) средние значения рангов, 2) стандартные отклонения рангов, 3) кол-во оцениваемых объектов и 4) тип матрицы. Нажимаем Анализ и выбираем Основные статистики и таблицы
Создание матрицы для расчета ФА Теперь нужно создать матрицу такой структуры, по которой Statistica сможет осуществить факторный анализ. Необходимо, чтобы матрица, помимо значений корреляций между переменными, включала еще 4 строки под ними: 1) средние значения рангов, 2) стандартные отклонения рангов, 3) кол-во оцениваемых объектов и 4) тип матрицы. Нажимаем Анализ и выбираем Основные статистики и таблицы



 В итоге мы получили корреляционную матрицу для ФА, которую сможет прочитать Statistica. Однако, корреляционный анализ здесь был осуществлен коэффициентом Пирсона. Поэтому данную корреляционную матрицу (5 х5) нужно заменить на посчитанную нами коэффциентом Кендалла (скопировать и вставить).
В итоге мы получили корреляционную матрицу для ФА, которую сможет прочитать Statistica. Однако, корреляционный анализ здесь был осуществлен коэффициентом Пирсона. Поэтому данную корреляционную матрицу (5 х5) нужно заменить на посчитанную нами коэффциентом Кендалла (скопировать и вставить).
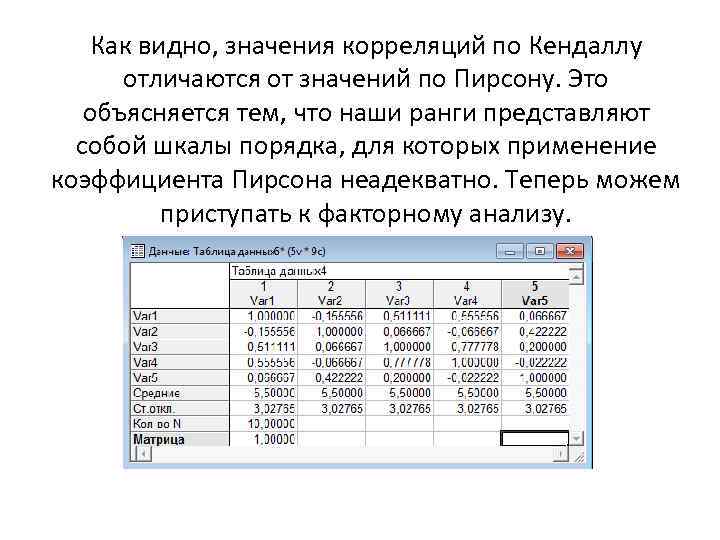 Как видно, значения корреляций по Кендаллу отличаются от значений по Пирсону. Это объясняется тем, что наши ранги представляют собой шкалы порядка, для которых применение коэффициента Пирсона неадекватно. Теперь можем приступать к факторному анализу.
Как видно, значения корреляций по Кендаллу отличаются от значений по Пирсону. Это объясняется тем, что наши ранги представляют собой шкалы порядка, для которых применение коэффициента Пирсона неадекватно. Теперь можем приступать к факторному анализу.

 Переменные → выделяем все 5 переменных Var 1 Var 5 → в поле Файл данных ставим Корреляционная матрица → ОК
Переменные → выделяем все 5 переменных Var 1 Var 5 → в поле Файл данных ставим Корреляционная матрица → ОК
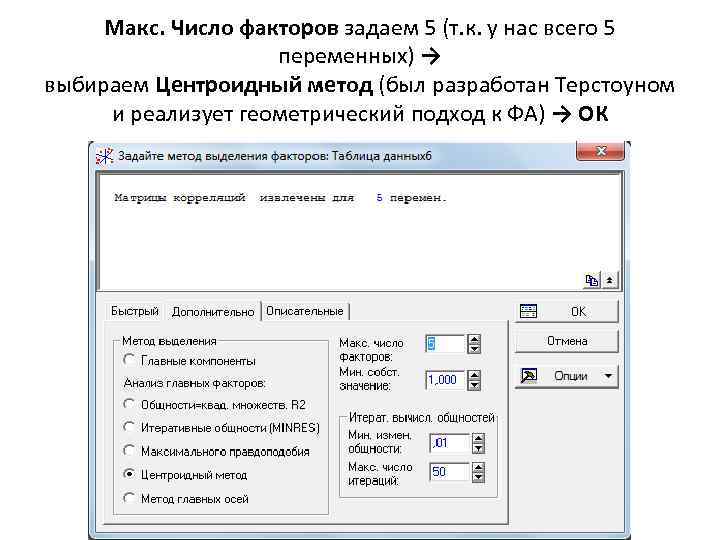 Макс. Число факторов задаем 5 (т. к. у нас всего 5 переменных) → выбираем Центроидный метод (был разработан Терстоуном и реализует геометрический подход к ФА) → ОК
Макс. Число факторов задаем 5 (т. к. у нас всего 5 переменных) → выбираем Центроидный метод (был разработан Терстоуном и реализует геометрический подход к ФА) → ОК
 Программа выделила 2 фактора. Чтобы посмотреть факторные нагрузки, нажимаем кнопку Факторные нагрузки. Чтобы построить факторную диаграмму, нажмем 2 М график нагрузок.
Программа выделила 2 фактора. Чтобы посмотреть факторные нагрузки, нажимаем кнопку Факторные нагрузки. Чтобы построить факторную диаграмму, нажмем 2 М график нагрузок.



 Statgraphics Centurion q. Факторный анализ q. Выделение факторных нагрузок q. Построение факторной диаграммы q. Построение объектной диаграммы
Statgraphics Centurion q. Факторный анализ q. Выделение факторных нагрузок q. Построение факторной диаграммы q. Построение объектной диаграммы
 В программе не предусмотрена возможность заложить свою корреляционную матрицу, поэтому начинаем сразу с анализа наших рангов. Вбиваем наши ранги и выбираем Analyze → Variable Data → Multivariate Methods → Factor Analysis
В программе не предусмотрена возможность заложить свою корреляционную матрицу, поэтому начинаем сразу с анализа наших рангов. Вбиваем наши ранги и выбираем Analyze → Variable Data → Multivariate Methods → Factor Analysis

 В итоге, программа выделила нам 2 фактора с уровнем объясненной дисперсии 82, 468 %. Это значит, что этими факторами объясняется 82, 468 % (почти 4/5) всей нашей информации по пяти переменным.
В итоге, программа выделила нам 2 фактора с уровнем объясненной дисперсии 82, 468 %. Это значит, что этими факторами объясняется 82, 468 % (почти 4/5) всей нашей информации по пяти переменным.
 График каменистой осыпи (2 фактора) На графике показано, что вся объясненная информация приходится на 1 и 2 факторы (2 точки над красной линией)
График каменистой осыпи (2 фактора) На графике показано, что вся объясненная информация приходится на 1 и 2 факторы (2 точки над красной линией)
 Факторные нагрузки Нажимаем Tables (вторая кнопка слева на панели) Ставим галочку возле Extraction Statistics → ОК
Факторные нагрузки Нажимаем Tables (вторая кнопка слева на панели) Ставим галочку возле Extraction Statistics → ОК
 Как видно факторные нагрузки на уровне десятых отличаются от тех, что мы получили при ручном расчете и в Statistica. Объясняется это тем, что в Statgraphics нельзя заложить свою корреляционную матрицу и программа всегда считает коэффициентом Пирсона, что не адекватно для данных в шкалах порядка.
Как видно факторные нагрузки на уровне десятых отличаются от тех, что мы получили при ручном расчете и в Statistica. Объясняется это тем, что в Statgraphics нельзя заложить свою корреляционную матрицу и программа всегда считает коэффициентом Пирсона, что не адекватно для данных в шкалах порядка.
 Факторная диаграмма Нажимаем Graphs (третья кнопка слева на панели) Ставим галочку возле 2 D Factor Plot (если бы у нас было больше 2 -х факторов, мы бы поставили галочку напротив 3 D Factor Plot, чтобы получить трехмерный график) → ОК
Факторная диаграмма Нажимаем Graphs (третья кнопка слева на панели) Ставим галочку возле 2 D Factor Plot (если бы у нас было больше 2 -х факторов, мы бы поставили галочку напротив 3 D Factor Plot, чтобы получить трехмерный график) → ОК
 Мы получили факторную матрицу после вращения. Отрезки (проекции точек, образованные факторными нагрузками) 2 и 5 расположены близко к оси y (стремятся к 0) и удалены от оси x. Это значит, что координаты этих точек по оси x (которая соответствует первому фактору) представлены низкими значениями (0, 6). Следовательно шкалы 2 и 5 представляют собой 1 фактор. По такому же принципу отрезок 1, говорит о том, что шкалы 1, 3 и 4 представляют собой 2 фактор.
Мы получили факторную матрицу после вращения. Отрезки (проекции точек, образованные факторными нагрузками) 2 и 5 расположены близко к оси y (стремятся к 0) и удалены от оси x. Это значит, что координаты этих точек по оси x (которая соответствует первому фактору) представлены низкими значениями (0, 6). Следовательно шкалы 2 и 5 представляют собой 1 фактор. По такому же принципу отрезок 1, говорит о том, что шкалы 1, 3 и 4 представляют собой 2 фактор.
 Объектная диаграмма Нажимаем Graphs (третья кнопка слева на панели) Ставим галочку возле 2 D Scatterplot (если бы у нас было больше 2 -х факторов, мы бы поставили галочку напротив 3 D Scatterplot, чтобы получить трехмерный график) → ОК
Объектная диаграмма Нажимаем Graphs (третья кнопка слева на панели) Ставим галочку возле 2 D Scatterplot (если бы у нас было больше 2 -х факторов, мы бы поставили галочку напротив 3 D Scatterplot, чтобы получить трехмерный график) → ОК
Если значения прогнозируемого параметра зависят не от времени, а от каких-либо других факторов, то используется факторный статистический анализ. Обычно для этого с помощью ПЭВМ по известной статистике подбирается аппроксимирующая функция одной или многих переменных, которая и служит моделью для выработки прогноза. Рассмотрим эту процедуру на примере.
Пример.
Предприниматель реализует мороженное у станции метро "Политехническая". Он должен сделать заказ на будущую педелю с разбивкой по дням. Каждое утро заказанное количество товара завозится на его точки реализации. При неправильном заказе (прогнозе) в конце дня мороженного может не хватить тогда имеет место упущенная выгода, либо часть его останется нереализованной и тогда возникнут проблемы с его сохранением до завтрашнего утра. Требуется выявить факторы, определяющие продажи, собрать статистику продаж и значений этих факторов, далее разработать прогноз продаж мороженного на будущую неделю. Предполагается, что дело происходит в разгаре лета.
Решение.
Среди факторов, влияющих на продажи мороженного в разгар лета, отобраны два наиболее существенных: температура воздуха и день недели. Отметим, что второй фактор имеет логический характер, что создает дополнительные трудности решения. Собранная за три недели статистика представлена в таблице 3.1. Будем считать, что к моменту прогнозирования объема продаж известен прогноз погоды (температуры) на будущую неделю.
Подходов к решению этой задачи несколько. Рассмотри» сначала наиболее распространенный классический метод.
Для устранения влияния на зависимость продаж от температуры логической переменной - дня недели рассчитаем коэффициенты приведения для каждого дня недели к среднедневной продаже (табл.. 3.2). Затем с помощью этих коэффициентов пересчитаем исходные данные о продажах (получим приверженные фактические продажи. показанные в табл..3.3
и на рис. 3.2). Аппроксимация этой зависимости прямой, описываемой уравнением 0=4,1 t 0 +23,76. дает очень хорошие результаты (коэф. корреляции 0,9). В табл.. 3.3 даны также результаты расчетов продаж на основе полученной трендовой линейной зависимости. С использованием этой же модели можно спрогнозировать приведенные продажи на будущую неделю, а затем с помощью коэффициентов приведения перечитать их в индивидуальные прогнозы на каждый день недели (табл. 3.4).


Значения коэффициентов а и в при линейной аппроксимации могут быть рассчитаны как на ПЭВМ, так и вручную по формулам
Попытка связать объемы продаж только с температурой, игнорируя влияние на них дня недели, несостоятельна. Это наглядно видно из графика (рис. 3.1) и значения коэффициента корреляции.
Другой, менее точный подход к решению состоит в том, чтобы в единый статистический массив свести данные с понедельника по четверг без разделения их на дни педели. То же проделать с данными пятницы, субботы и воскресенья. Для каждого из массивов подобрать аппроксимирующую кривую зависимости объемов продаж от температуры и на ее основе делать прогноз.
При наличии большей, чем сейчас, статистики эту процедуру можно осуществлять отдельно для каждого дня недели, что упростит и сделает более точным решение этой задачи. При этом плохо лишь то, что с ростом объема статистик на прогноз все большее влияние будет оказывать фактор сезонности, который мы до сих пор игнорировали.

Факторный анализ со статистической точки зрения связан с поиском новых признаков, характеризующих объекты наблюдения на основе имеющейся информации, которая содержится в измеренных значениях k исходных признаков. Всю информацию об п объектах наблюдения можно представить в виде матрицыили прямоугольной таблицы "объект – признак" (табл. 5.6).
Таблица 5.6
Таблица "объект (i) – признак (/)"
Для дальнейшего анализа удобнее использовать матрицу наблюдаемых стандартизованных признаков, которые тоже относятся к категории измеримых, как рассчитанных непосредственно по результатам произведенных наблюдений
Стандартизация производится в соответствии с заменой (5.3), но обычно неизвестные математические ожидания и дисперсии n"j заменяются их выборочными аналогами: выборочной средней
и несмещенной оценкой дисперсии
либо асимптотически несмещенной оценкой дисперсии
Средние значения стандартизованных переменных равны нулю (), а дисперсии – единице ().
Связь новых переменных с наблюдаемыми признаками в факторном анализе аналогична регрессионной, но с тем существенным отличием, что эти новые объясняющие переменные, или факторы, неизвестны и нуждаются в идентификации. В моделях факторного анализа используются общие и индивидуальные факторы. Общие факторы связаны значимыми коэффициентами более чем с одной измеримой переменной. Каждый из индивидуальных факторов v. связан только с однойу-й измеримой переменной. При этом обычно предполагается, что индивидуальные факторы некоррелированы между собой и с общими факторами. Кроме того, для удобства факторы выбираются как стандартизованные:
Второй индекс переменныхобозначает номер объекта наблюдения i - 1,2,..., п. Первый индекс j = 1,2,...,k характеризует номер исходного признака Zjj и соответствующего ему индивидуального эффекта vjY, а для g lt первый индекс / = 1,2,..., от обозначает номер общего фактора.
Коэффициенты при общих факторах можно свести в матрицу
а коэффициенты при индивидуальных факторах для дальнейшего матричного представления модели будут диагональными элементами в диагональной матрице
Включающая нагрузки всех факторов общая матрица коэффициентов, или матрица факторного отображения, будет представлять собой результат объединения элементов обеих матриц:

Матрица значений общих факторов представляет собой матрицу размерности т х п, где т < k:
Матрица значений индивидуальных факторов имеет размерность kxn:
Общая матрица значений факторов может быть образована как результат объединения матриц общих и индивидуальных факторов:
С учетом введенных обозначений модель факторного анализа в матричной форме может быть представлена в виде
Модель факторного анализа с учетом неполного содержания исходной информации об объектах исследования в новой системе координат меньшей размерности (m < k) неизбежно будет содержать помимо общности в виде информации об объектах в системе координат общих факторов и специфичность, представляемую в виде значений характерных факторов. В то же время с учетом случайности выборки и погрешности измерения нормированное наблюдаемое значение содержит истинное значение, индивидуальную особенность Indjj каждого объекта и ошибку измерения е":
В рамках статистического подхода под истинным значением понимается математическое ожидание признака, вторая и третья составляющие характеризуют отклонение отдельного показателя на данном объекте от среднего. Если первая составляющая является общей статистической характеристикой совокупности объектов исследования, то вторая и третья компоненты являются носителями особенностей, присущих данному объекту и методу измерения. В процессе управления важнейшим моментом являются знание и умение учитывать индивидуальные черты отдельных объектов исследования.
Характеристика вариативности – дисперсия – для нормированного значения наблюдаемого признака может быть представлена в следующем виде:
 (5.14)
(5.14)
Ошибка измерения обычно оказывается значительно меньше вариативной компоненты, поэтому их часто объединяют . Однако поскольку вариативная составляющая и ошибки измерения возникают независимо друг от друга, то их рассматривают как некоррелированные.
Рассмотрим слагаемые, содержащие сомножитель, величина которого является дисперсией произвольного общего факторапосле нормировки:
Величина дисперсии нормированного общего фактора равна единице:
Рассмотрим в формуле (5.14) слагаемые, содержащие сомножитель . Это коэффициент корреляции между двумя общими факторами, т.е.
После введения обозначения для коэффициента корреляции общих и индивидуальных эффектов
выражение (5.14) можно представить в виде
Из этого представления следует, что
Так как характерный фактор присущ только данной)-й переменной и некоррелирован с общими факторами, тои выражение (5.15) можно упростить:
![]()
Дальнейшее упрощение может быть получено для некоррелированных общих факторов, когда и, тогда
В этом случае дисперсия признакаравна сумме относительных вкладов в дисперсию этого признака каждого из т общих и одного характерного фактора.
Компонент общей дисперсииназывается общностью показателя Zj, т.е. суммой относительных вкладов всех т общих факторов в дисперсию признака Zj. Вклад в дисперсию признака z ) характерного фактора Vj, или характерность, определяется слагаемым bj. В свою очередь дисперсия характерного фактора состоит из двух составляющих: связанной со спецификой параметра Sj и связанной с ошибками измерений Е у
Если факторы специфичности Sj и ошибки Ej некоррелированы между собой, то модель факторного анализа примет вид
Вклад характерного фактора в дисперсию признака может быть представлен следующим образом:
Если выделить из дисперсии признака составляющую ошибки, то получим характеристику, называемую надежностью:
Вклад фактора /,. в суммарную дисперсию всех признаков определяется соответствующей суммой квадратов коэффициентов при нормированных значениях:
Вклад всех общих факторов в суммарную дисперсию признаков рассчитывается как сумма вкладов всех факторов:
Отношение этой суммы к размерности исходного признакового пространства
называют полнотой факторизации.
Исходные данные матрицы X (или Z) позволяют получить матрицу парных коэффициентов корреляции R. Для воспроизведения всех связей переменных в корреляционной матрице может быть использована матрица К = (А В):
![]()
Введем обозначение для первого слагаемого – редуцированной корреляционной матрицы: /¾ = ЛЛ Т.
Матрицу ВВ" вследствие того, что В является диагональной матрицей, можно представить в виде ВВ Т = В 2.
Таким образом, матрица парных коэффициентов корреляции исходных показателей может быть представлена в виде суммы:
В то время как R является корреляционной матрицей с единицами на главной диагонали, матрица R h представляет собой корреляционную матрицу с общностями на главной диагонали.
Для стандартизованных исходных признаков 7 корреляционная матрица R тождественна ковариационной матрице 2. Если рассматривать данные как выборку из генеральной совокупности, то определенная по выборочным данным матрица 2 (или К) является оценкой истинной ковариационной (корреляционной) матрицы. Несмещенная оценка может быть получена в виде
Рассчитаем редуцированную корреляционную матрицу с учетом равенства (5.4), используя для восстановления нормированных исходных признаков только общие факторы:
Выражение, стоящее между А и А т, является корреляционной матрицей стохастических связей между общими факторами
При этом общее выражение для редуцированной корреляционной матрицы примет вид
Если общие факторы некоррелированы между собой, то матрица С будет единичной, и при этом
Два последних выражения представляют собой фундаментальную теорему факторного анализа.
Пример 5.2
По данным о численности (дг,) и фонде заработной платы (,v2) пяти строительных организаций проведем факторный анализ методом главных компонент. Дано:
Решение
Рассчитаем выборочные характеристики переменных т, и Выборочный коэффициент корреляции равен
![]()
Преобразуем матрицу X в матрицу нормированных значений Z с элементами , где
Матрица парных коэффициентов корреляции имеет вид
Для определения собственных значений матрицы R рассмотрим характеристическое уравнение
Отсюда следует, что
Так как по условию компонентного анализа, то, где,
– соответственно дисперсии и вклад первой и второй главных компонент в суммарную дисперсию, равную
Относительный вклад компонент в суммарную дисперсию равен Таким образом,
Определим матрицу собственных векторов из уравнения Собственный векторнаходим из условия
Подставляя полученные значения, получим
откудаили
Нормированный собственный вектор, соответствующий, равен
Собственный вектор V 2 найдем, решив уравнение
откуда.или
Нормированный собственный вектор, соответствующий Х2. равен
тогда нормированная матрица собственных векторов имеет вид
![]()
Матрицу факторных нагрузок найдем по формуле ![]() . Подставив полученные значения, получим
. Подставив полученные значения, получим
Матрицу факторных нагрузок используют для интерпретации главных компонент, так как элементы матрицы а }Х) = характеризуют тесноту связи между Хгм признаком и /0-й главной компонентой. В нашем примере первая главная компонента тесно связана с показателями.г, и.г2, а /, характеризует размер предприятия.
Матрицу значений главных компонент F можно получить по формуле
Предварительно найдем обратную матрицу. Так как то
Тогда 
Как уже отмечалось, матрица F. которую мы получили, характеризует пять строительных организаций в пространстве главных компонент. Ее можно использовать в задачах классификации и регрессионного анализа. Например, классификация организации но первой главной компоненте /, характеризующей размер предприятий, позволяет ранжировать их в порядке возрастания следующим образом: 4; 1:2: 5: 3. Значения главных компонент определены с точностью до знака, поэтому они могли бы оказаться противоположными для всех объектов, и проведенная ранжировка характеризовала бы размеры предприятий в порядке уменьшения. Определить правильность выбранного знака можно по значениям исходных показателей для крайних проранжированных объектов.
Пример 5.3
На основе информации о значениях семи исходных признаков получены два общих некоррелированных фактора. По известной матрице весовых коэффициентов двух общих факторов Л требуется воспроизвести редуцированную корреляционную матрицу R h, определить редуцированную корреляционную матрицу для случая использования только первого общего фактора R 1 и только второго общего фактора R" при условии, что дисперсия первого общего фактора больше, чем дисперсия второго.
Решение
1. Получим матрицу R h.
Произведем умножение матрицы А на А т и получим редуцированную корреляционную матрицу /?л. т.е. восстановленную из модели факторного анализа при условии, что факторы некоррелированы:

В матрице R /t на главной диагонали стоят дисперсии, представляющие общности, суммарный вклад в переменные имеющихся двух общих факторов.
2. Получим матрицу R 1.
Зададимся вопросом: что было бы, если бы мы пренебрегли вторым общим фактором и провели интерпретацию на основании только первого общего фактора? Какая редуцированная корреляционная матрица R 1 была бы воспроизведена?

Воспроизведенная, или редуцированная, по первому общему фактору матрица восстанавливает связи, объясняемые первым собственным вектором матрицы А. В матрице Д"на главной диагонали стоят вклады в дисперсию первого столбца фактора соответствующих переменных. Они совпадают с вкладами признаков в дисперсию первого фактора aj t.
Как первая, так и вторая воспроизведенные матрицы не отражают всей информации процесса. При этом вторая матрица R" отражает меньше информации, чем первая R 1. Это объясняется тем, что R 1 воспроизводит связи, соответствующие дисперсии первого фактора, которая больше дисперсии второго фактора. Однако и более полная матрица R/, не производит связей, определяемых характерными факторами, так как она объединяет весовые коэффициенты только общих факторов. Необъясненная же часть информации матрицами R/, и А приходится на характерные факторы.
При использовании факторного анализа исследователь сталкивается с различными проблемами. Наиболее часто они возникают в процессе содержательной интерпретации результатов анализа. Многие из проблем носят частный характер, не относящийся непосредственно к факторному анализу и присущий определенному классу задач, например наличие плохо обусловленных матриц парных коэффициентов корреляций, присущее классу экономико-статистических задач.
Среди проблем проведения факторного анализа можно выделить проблемы робастности, общности, выбора факторов, вращения факторов и оценки их значений и содержательной интерпретации, а также проблему построения динамических моделей.
В классическом факторном анализе на основе исходной таблицы "объект – признак" (см. табл. 5.6) формируется матрица нормированных значений исходных признаков. Опыт решения практических задач показывает, что наличие грубых ошибок данных при многомерном анализе может привести к дальнейшим трудностям. Малую чувствительность к наличию грубых ошибок данных обеспечивают робастные оценки параметров: среднего значения и дисперсии или среднего квадратического отклонения.
Рассчитываемая матрица парных коэффициентов корреляции является симметрической матрицей порядка к. Она является диагональной, и на се главной диагонали стоят единицы, соответствующие дисперсиям исходных нормированных показателей. Данная матрица R является исходной для проведения компонентного анализа. Для факторного анализа необходимо получить редуцированную матрицу /?/,.
Редуцированная корреляционная матрица /¾ служит основной для факторного анализа. Она также является симметрической порядка k, но на ее главной диагонали вместо единиц стоят общности hj. На основе этой матрицы рассчитывается матрица весовых коэффициентов Л. Ее элементы являются характеристиками стохастической связи между исходными признаками и общими факторами.
При переходе от редуцированной корреляционной матрицы к матрице весовых коэффициентов необходимо решить проблему нахождения факторов, включающую вопросы определения числа извлекаемых общих факторов и их вида. Значения весовых коэффициентов являются координатами признаков на новых осях координат. Этими координатными осями являются общие факторы. Чаще всего для их нахождения используется метод главных компонент.
Задача воспроизведения матрицы /?>, по матрице А не имеет однозначного решения. Выбор одной из возможных матриц является составной частью решения задачи вращения координатных осей.
После получения новой интегральной системы измерения – общих факторов – можно оценить значения индивидуальных факторов для каждого объекта исследования.
Сопоставление факторных решений в течение длительного периода обеспечивается динамическим моделированием, позволяющим выявить те признаки, влияние которых в будущем будет снижаться или, наоборот, возрастать.
Предыдущая статья: Суп из судака поможет разнообразить низкокалорийный рацион Следующая статья: Маринованные помидоры с морковью и луком на зиму Помидоры с морковью и чесноком